def get_r_scaled(x, scale="log2"):
x = np.asarray(x, dtype=float)
powers = np.arange(np.ceil(np.log2(x.min())), np.floor(np.log2(x.max())) + 1)
xlabels = 2 ** powers
if scale == "log10":
xscale = np.log10(x)
xticks = np.log10(xlabels)
elif scale == "log2":
xscale = np.log2(x)
xticks = np.log2(xlabels)
else:
xscale = x
xticks = xlabels
xlabel_str = [f"{r:g}" for r in xlabels]
return xscale, xticks, xlabel_str
def style_blank_axis(ax):
ax.tick_params(bottom = False, top = False, left = False, right = False,
labelbottom = False, labeltop = False, labelleft = False, labelright = False)
def style_colorbar_yticks(cbar, cmap, norm):
for tick, value in zip(cbar.ax.yaxis.get_major_ticks(), cbar.ax.get_yticks()):
color = cmap(norm(value))
tick.tick1line.set_markeredgecolor(color)
tick.tick2line.set_markeredgecolor(color)
tick.tick1line.set_color("none")
tick.tick2line.set_color("none")
# for tick_label, value in zip(cbar.ax.get_yticklabels(), cbar.ax.get_yticks()):
# tick_label.set_color(cmap(norm(value)))
def make_line_plots_with_colorbar_inset(ax, x, y, ycols,
ylabel="", cbar_label="", cbar_xpos="", show_cbar=True,
vcenter=None, cmap=None, norm=None):
"""
Create K = len(ycols) line plots, color maps to values in ycols
x : ndarray(N,)
y : ndarray(N, K), columns of y correspond to values in k_list
Returns cmap, norm for future use.
"""
from matplotlib.cm import ScalarMappable
if cmap is None:
cmap = mpl_cmaps.get_cmap("viridis").copy()
if norm is None:
vmin = min(ycols)
vmax = max(ycols)
if vcenter is None: vcenter = (vmin + vmax) / 2.
norm = mpl_colors.TwoSlopeNorm(vmin=vmin, vcenter=vcenter, vmax=vmax)
for i, k in enumerate(ycols):
ax.plot(x, y[:, i], color=cmap(norm(i)))
ax.set_ylabel(ylabel)
if show_cbar:
cax = ax.inset_axes([cbar_xpos, 0.15, 0.02, 0.7])
sm = ScalarMappable(norm=norm, cmap=cmap)
cbar = plt.colorbar(sm, cax=cax, fraction = 0.1)
# Colorbar style
style_blank_axis(cbar.ax)
cbar.ax.tick_params(right=True, labelright=True, pad=5, width=2, length=5)
cbar.set_label(cbar_label, labelpad = 10)
cbar.ax.yaxis.set_label_position('left')
style_colorbar_yticks(cbar, cmap, norm)
for side, border in list(cbar.ax.spines.items()):
border.set_visible(False)
return cmap, norm
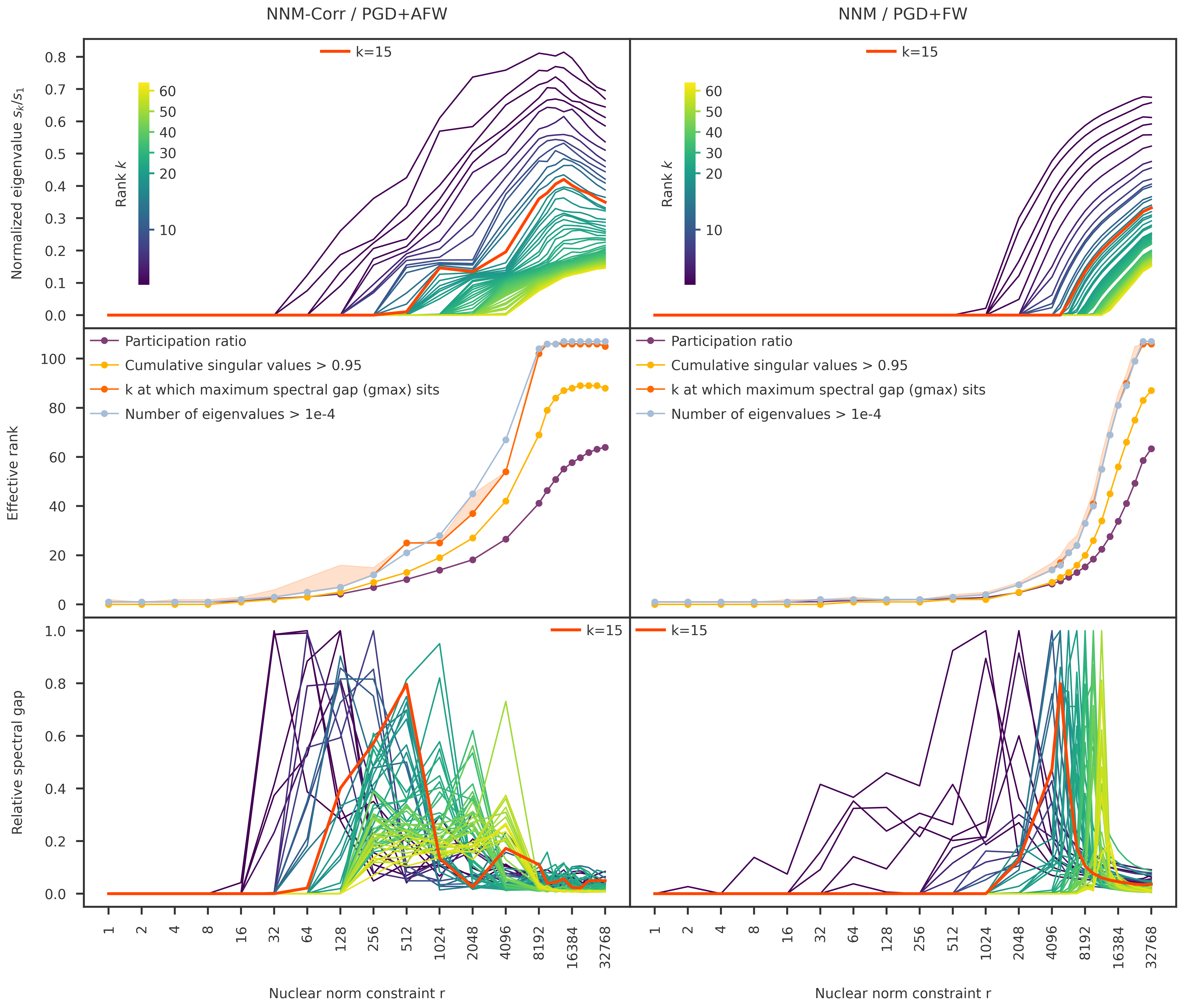
def make_singular_value_plots(ax1, ax2, ax3, prefix,
subspace_out_dir, r_scale='log10', show_yaxis=True, k_highlight=20):
# load data
subspace_df = load_subspace_npz(subspace_out_dir, prefix)
df = get_subspace_spectrum(subspace_df, use_mean=True)
nucnorms = df["nucnorm"].to_numpy(dtype=float)
r_fits = nucnorms * np.sqrt(0.5)
# common x-axis for all plots
x, xticks, xlabels = get_r_scaled(nucnorms, scale=r_scale)
ylabel=""
# -- ax1: fan of normalized singular values --
k_list = np.arange(4, 65)
k_center = 15
y = get_singular_value_metrics(df, k_list, metric="norm_value")
show_cbar = True
if show_yaxis:
# show_cbar = True
ylabel=r"Normalized eigenvalue $s_k / s_1$"
cmap, norm = make_line_plots_with_colorbar_inset(
ax1, x, y, k_list,
show_cbar=show_cbar,
ylabel=ylabel, cbar_label=r"Rank $k$", cbar_xpos=0.1,
vcenter=k_center)
ax1.plot(x, y[:, k_highlight-1], color='orangered', lw=3, label=f"k={k_highlight:d}")
ax1.legend(frameon = False, handlelength = 2, loc='upper center')
# -- ax2: effective ranks --
rank_methods = {
"participation_ratio":
{"thres": None, "label": "Participation ratio"},
"energy":
{"thres": 0.95, "label": f"Cumulative singular values > 0.95"},
"spectral_gap":
{"thres": None, "label": "k at which maximum spectral gap (gmax) sits"},
"count":
{"thres": 1e-4, "label": "Number of eigenvalues > 1e-4"},
"spectral_gap_loose":
{"thres": 0.7, "label": "Max k at which spectral gap > 70% gmax"},
}
ranks = {}
rank_lines = {}
for m, mdict in rank_methods.items():
ranks[m] = get_effective_ranks(df, nucnorms, method=m, thres=mdict["thres"])
if m != "spectral_gap_loose":
rank_lines[m], = ax2.plot(x, ranks[m], 'o-', label=mdict["label"])
ax2.fill_between(x, ranks["spectral_gap"], ranks["spectral_gap_loose"],
color=rank_lines["spectral_gap"].get_color(), alpha=0.2)
if show_yaxis:
ylabel="Effective rank"
ax2.legend(frameon = False, handlelength = 2)
ax2.set_ylabel(ylabel)
# -- ax3: relative spectral gap --
# k_list = [8, 10, 12, 15, 20, 25, 30, 40]
y = get_singular_value_metrics(df, k_list, metric="relative_gap")
for i, k in enumerate(k_list):
# ax3.plot(x, y[:, i], 'o-', label=f"{k}")
ax3.plot(x, y[:, i], color=cmap(norm(i)))
ax3.plot(x, y[:, k_highlight-1], color='orangered', lw=3, label=f"k={k_highlight:d}")
if show_yaxis:
ylabel=r"Relative spectral gap"
ax3.legend(frameon = False, handlelength = 2)
ax3.set_ylabel(ylabel)
# -- mark the x-axis --
ax3.set_xticks(xticks)
ax3.set_xticklabels(xlabels, rotation=90)
ax3.set_xlabel("Nuclear norm constraint r")
return
fig = plt.figure(figsize=(20, 16))
gs = fig.add_gridspec(nrows=3, ncols=2, wspace=0, hspace=0)
ax1 = fig.add_subplot(gs[0, 0])
ax2 = fig.add_subplot(gs[1, 0])
ax3 = fig.add_subplot(gs[2, 0])
ax4 = fig.add_subplot(gs[0, 1], sharey=ax1)
ax5 = fig.add_subplot(gs[1, 1], sharey=ax2)
ax6 = fig.add_subplot(gs[2, 1], sharey=ax3)
for ax in (ax1, ax2, ax3, ax4, ax5, ax6):
style_blank_axis(ax)
ax.patch.set_alpha(0.0)
for ax in (ax1, ax2, ax3):
ax.tick_params(left=True, labelleft=True)
for ax in (ax3, ax6):
ax.tick_params(bottom=True, labelbottom=True)
prefix1 = "pgd_afw_nnm_corr"
make_singular_value_plots(
ax1, ax2, ax3,
prefix1, subspace_out_dir,
r_scale='log2', k_highlight=15,
)
ax1.set_title("NNM-Corr / PGD+AFW", pad=20)
prefix2 = "pgd_fw_nnm"
make_singular_value_plots(
ax4, ax5, ax6,
prefix2, subspace_out_dir,
r_scale='log2', show_yaxis=False, k_highlight=15,
)
ax4.set_title("NNM / PGD+FW", pad=20)
plt.savefig('figures/cvsr_singular_value_spectrum.pdf', bbox_inches='tight')
plt.show()