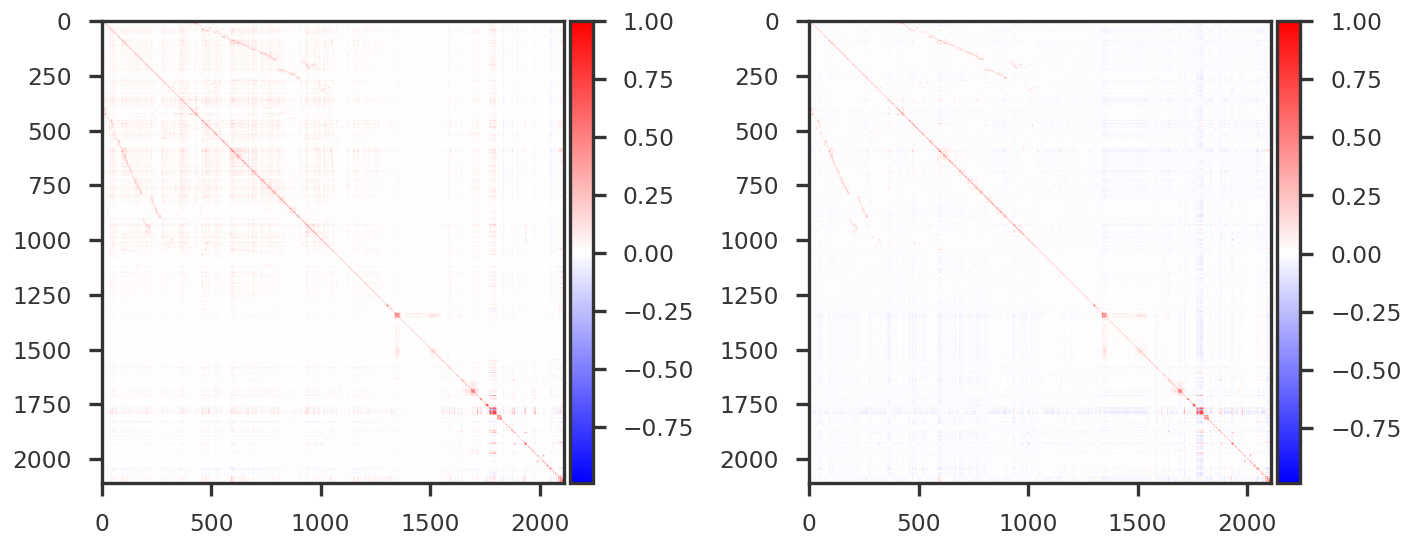
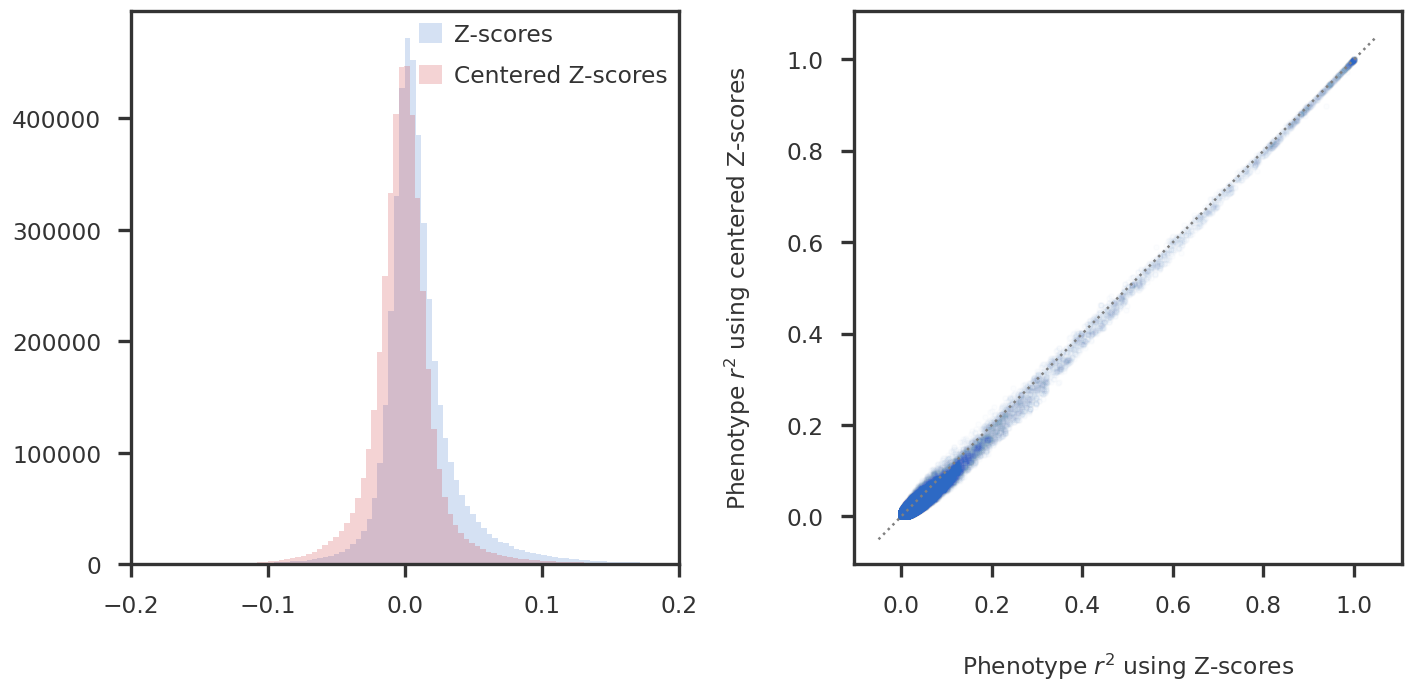
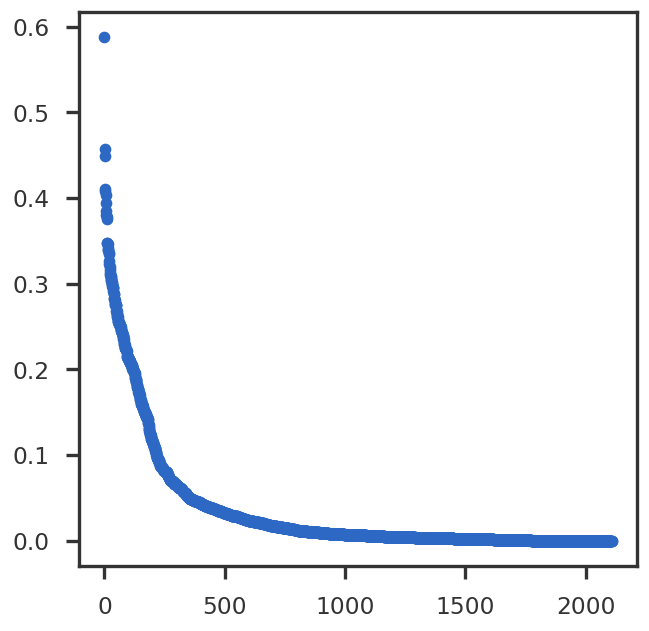
llm_method = "ls-da3m0ns/bge_large_medical"
llm_ctype = "agglomerative"
data_labels = get_llm_cluster_labels(trait_df.index.to_numpy(),
llm_clusters[llm_method][llm_ctype])
llm_categories = {
1: "Sleep, speech, lifestyle and environment",
2: "Cardiovascular system and hematologic disorders",
3: "Reproductive health and related disorders",
4: "Diabetes and lipid metabolism",
5: "Body composition, BMI, obesity and nutrition",
6: "Gastrointestinal disorders and related conditions",
7: "Respiratory disorders and infectious diseases",
8: "Neurological and musculoskeletal conditions",
9: "Medical examinations, follow-ups, and family history",
10: "Medications and allergies",
11: "Vision and refractive metrics",
12: "Ear, nose, throat, and dental health",
13: "Toxicology and supplemental medications",
14: "Dietary intake",
15: "Respiratory disorders and associated medications",
16: "Hematological metrics",
17: "Urinary system disorders",
18: "Alcohol consumption and related behavior",
19: "Demographics and life events",
20: "Ocular health",
21: "Self-reported health issues",
22: "Skin disorders and infections",
23: "Tobacco use and exposure",
24: "Blood pressure metrics",
25: "Carotid intima-media thickness (IMT)",
26: "Neoplasms and cancers",
27: "Metabolic and nutritional disorders",
28: "Thyroid-related conditions",
29: "Injuries and trauma",
30: "Mental health and emotional well-being"}