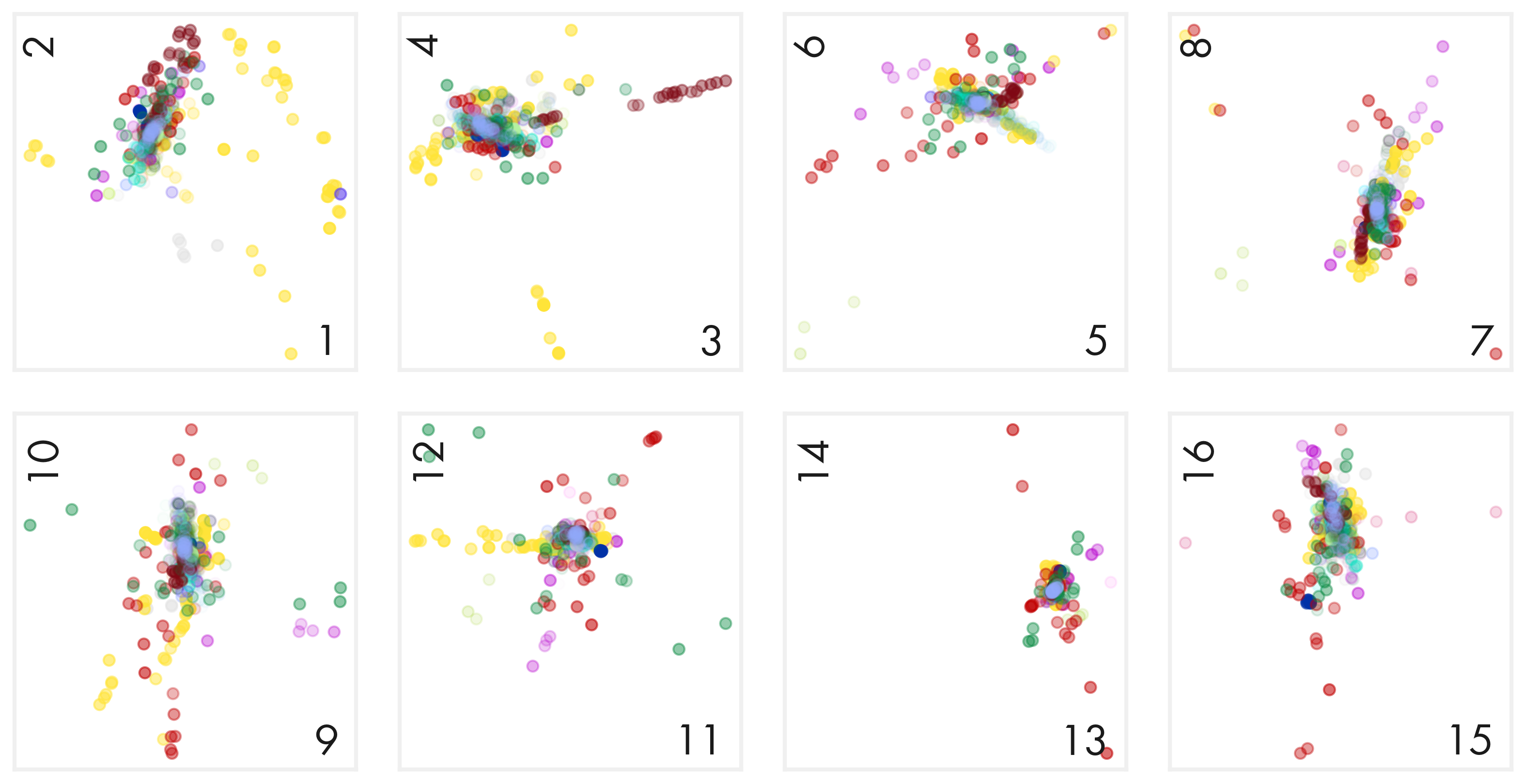
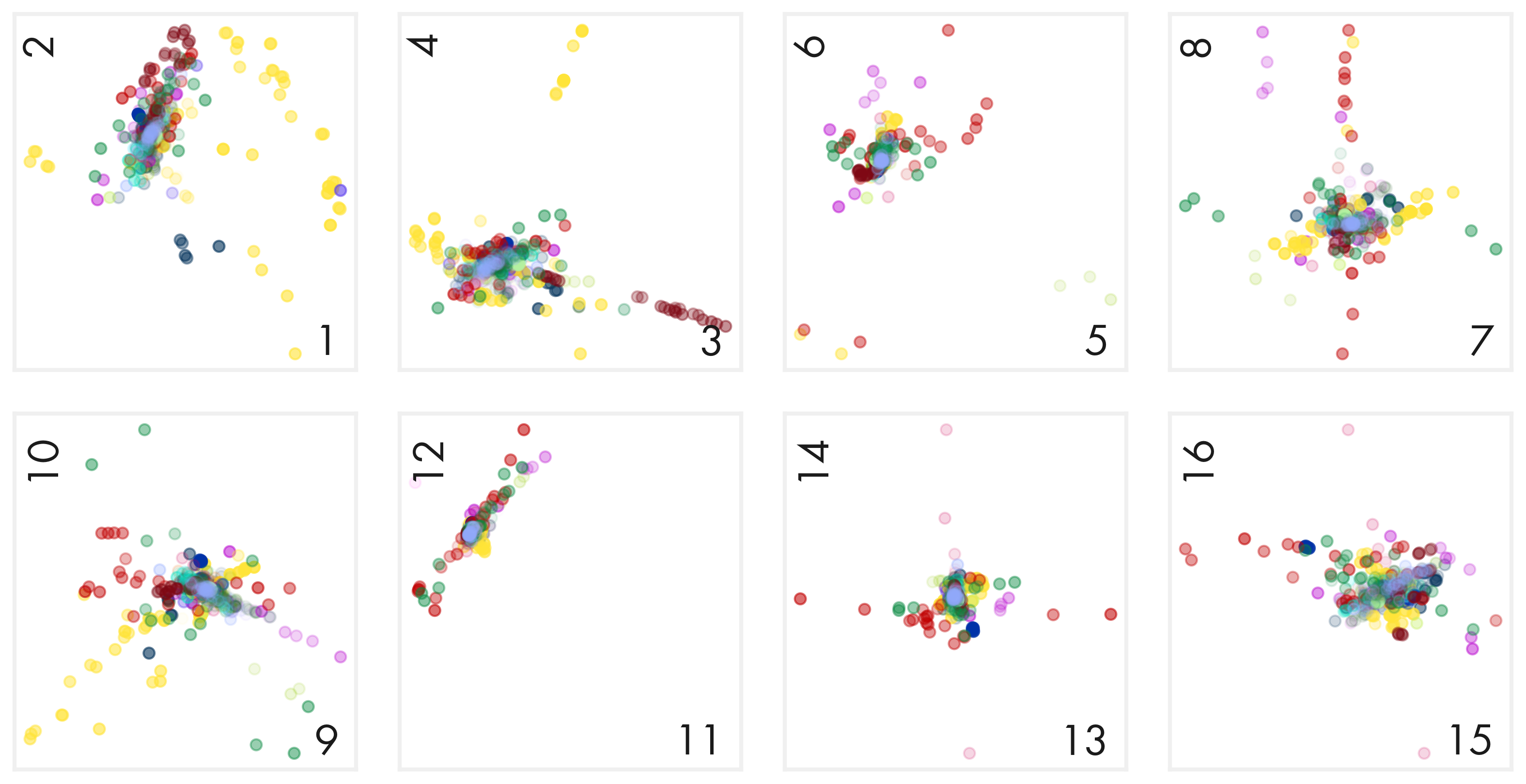
def make_single_plot_principal_components(ax, i, j, comps, labels, label_color_dict, alphas):
pc1 = comps[:, j]
pc2 = comps[:, i]
for label, color in label_color_dict.items():
idx = np.where(labels == label)[0]
if idx.shape[0] > 0:
ax.scatter(pc1[idx], pc2[idx], s = 30, alpha = alphas[idx], label = label, color = color)
return
def make_plot_principal_components_diag(pcomp, class_labels, class_colors,
h2 = None, alpha_factor = 10,
ncomp = 6,
subplot_h = 2.0, bgcolor = "#F0F0F0"):
'''
pcomp: principal components
class_labels: the class of each sample
class_colors: dict of class colors for each label
'''
nrow = ncomp - 1
ncol = ncomp - 1
figw = ncol * subplot_h + (ncol - 1) * 0.3 + 1.2
figh = nrow * subplot_h + (nrow - 1) * 0.3 + 1.5
fig = plt.figure(figsize = (figw, figh))
axmain = fig.add_subplot(111)
axs = list()
if h2 is None:
alpha_arr = np.full([pcomp.shape[0],], 0.6)
else:
alpha_arr = np.array([min(0.6, alpha_factor * abs(x)) for x in h2])
for i in range(1, nrow + 1):
for j in range(ncol):
ax = fig.add_subplot(nrow, ncol, ((i - 1) * ncol) + j + 1)
ax.tick_params(bottom = False, top = False, left = False, right = False,
labelbottom = False, labeltop = False, labelleft = False, labelright = False)
if j == 0: ax.set_ylabel(f"PC{i + 1}")
if i == nrow: ax.set_xlabel(f"PC{j + 1}")
if i > j:
ax.patch.set_facecolor(bgcolor)
ax.patch.set_alpha(0.3)
make_single_plot_principal_components(ax, i, j, pcomp, class_labels, class_colors, alpha_arr)
for side, border in ax.spines.items():
border.set_color(bgcolor)
else:
ax.patch.set_alpha(0.)
for side, border in ax.spines.items():
border.set_visible(False)
if i == 1 and j == 0:
mhandles, mlabels = ax.get_legend_handles_labels()
axs.append(ax)
axmain.tick_params(bottom = False, top = False, left = False, right = False,
labelbottom = False, labeltop = False, labelleft = False, labelright = False)
for side, border in axmain.spines.items():
border.set_visible(False)
#axmain.legend(handles = mhandles, labels = mlabels, loc = 'upper right', bbox_to_anchor = (0.9, 0.9))
plt.tight_layout()
return axmain, axs
def make_plot_principal_components(pcomp, class_labels, class_colors,
h2 = None, alpha_factor = 10,
ncomp = None, ncol = 4,
subplot_h = 2.0, bgcolor = "#F0F0F0"):
'''
pcomp: principal components
class_labels: the class of each sample
class_colors: dict of class colors for each label
'''
if ncomp is None: ncomp = pcomp.shape[1]
ncomp = int(ncomp / 2) * 2
nrow = int(np.ceil(ncomp / 2 / ncol))
figw = ncol * subplot_h + (ncol - 1) * 0.3 + 2.0
figh = nrow * subplot_h + (nrow - 1) * 0.3 + 1.5
fig = plt.figure(figsize = (figw, figh))
axmain = fig.add_subplot(111)
axs = list()
if h2 is None:
alpha_arr = np.full([pcomp.shape[0],], 0.6)
else:
alpha_arr = np.array([min(0.6, alpha_factor * abs(x)) for x in h2])
for i in range(int(ncomp / 2)):
ix = i * 2
iy = ix + 1
ax = fig.add_subplot(nrow, ncol, i + 1)
ax.tick_params(bottom = False, top = False, left = False, right = False,
labelbottom = False, labeltop = False, labelleft = False, labelright = False)
ax.set_xlabel(f"{ix + 1}", labelpad = -24, x = 0.95, ha = 'right')
ax.set_ylabel(f"{iy + 1}", labelpad = -24, y = 0.95, ha = 'right')
#ax.patch.set_facecolor(bgcolor)
ax.patch.set_alpha(0.0)
make_single_plot_principal_components(ax, iy, ix, pcomp, class_labels, class_colors, alpha_arr)
for side, border in ax.spines.items():
border.set_color(bgcolor)
axs.append(ax)
axmain.tick_params(bottom = False, top = False, left = False, right = False,
labelbottom = False, labeltop = False, labelleft = False, labelright = False)
for side, border in axmain.spines.items():
border.set_visible(False)
#axmain.legend(handles = mhandles, labels = mlabels, loc = 'upper right', bbox_to_anchor = (0.9, 0.9))
plt.tight_layout()
return axmain, axs
hex_colors_40 = [
"#e3e3e30d",
"#084609",
"#ff4ff4",
"#01d94a",
"#b700ce",
"#91c900",
"#5f42ed",
"#5fa200",
"#8d6dff",
"#c9f06b",
"#0132a7",
"#ffbb1f",
"#0080ed",
"#f56600",
"#3afaf5",
"#c10001",
"#01e698",
"#a20096",
"#00e2c1",
"#ff5ac8",
"#008143",
"#cd0057",
"#4aeeff",
"#8c001a",
"#b5f2a2",
"#5d177d",
"#a99900",
"#e299ff",
"#5b6b00",
"#96aeff",
"#a46f00",
"#007acb",
"#ff9757",
"#00a8e0",
"#ff708e",
"#baefc7",
"#622b25",
"#c8c797",
"#885162",
"#ffb7a5",
"#ffa3c3"]
llm_methods = [
"ls-da3m0ns/bge_large_medical",
"medicalai/ClinicalBERT",
"emilyalsentzer/Bio_ClinicalBERT",
]
llm_ctypes = ["community", "kmeans", "agglomerative"]
llm_clusters = {method : { x : None for x in llm_ctypes } for method in llm_methods}
llm_outdir = "/gpfs/commons/home/sbanerjee/work/npd/PanUKB/results/llm"
for method in llm_methods:
for ctype in llm_ctypes:
m_filename = os.path.join(llm_outdir, f"{method}/{ctype}_clusters.pkl")
with open(m_filename, "rb") as fh:
llm_clusters[method][ctype] = pickle.load(fh)
def get_llm_cluster_labels(selectidx, method, ctype):
clusteridx = np.full([selectidx.shape[0],], -1)
for i, ccomps in enumerate(llm_clusters[method][ctype]):
for idx in ccomps:
clusteridx[idx] = i
return clusteridx