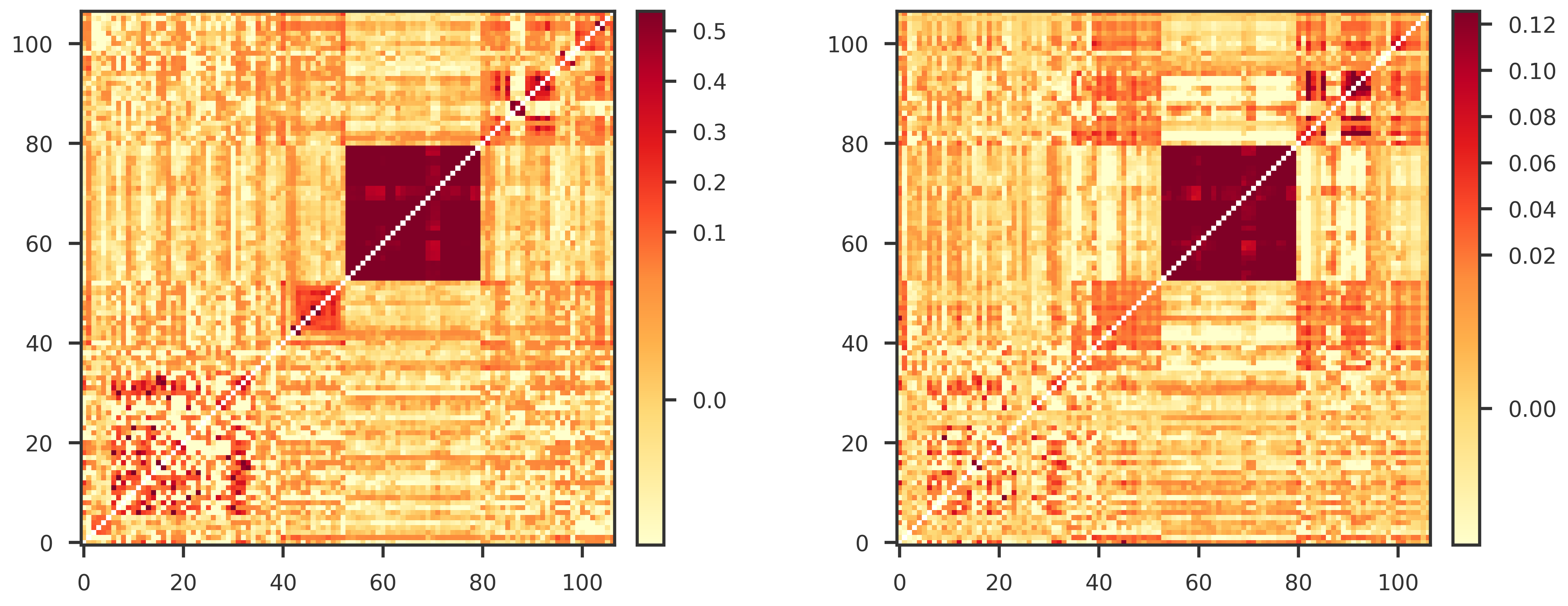
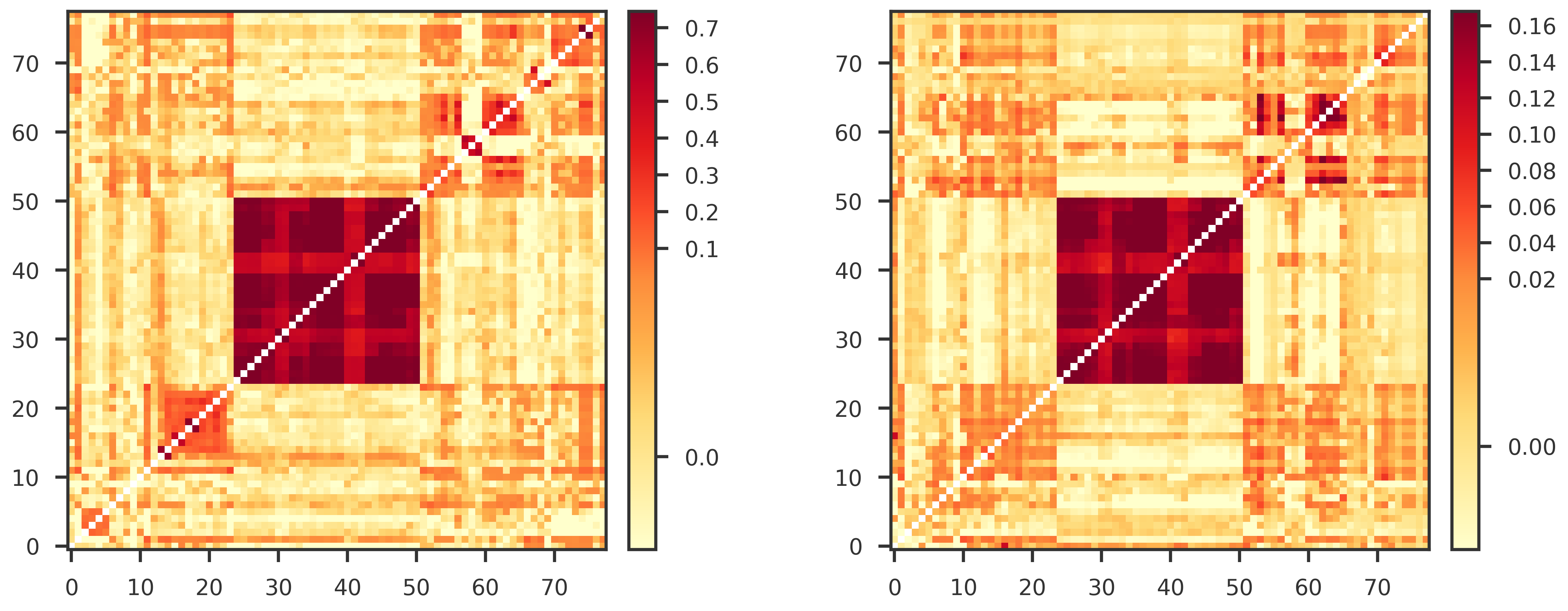
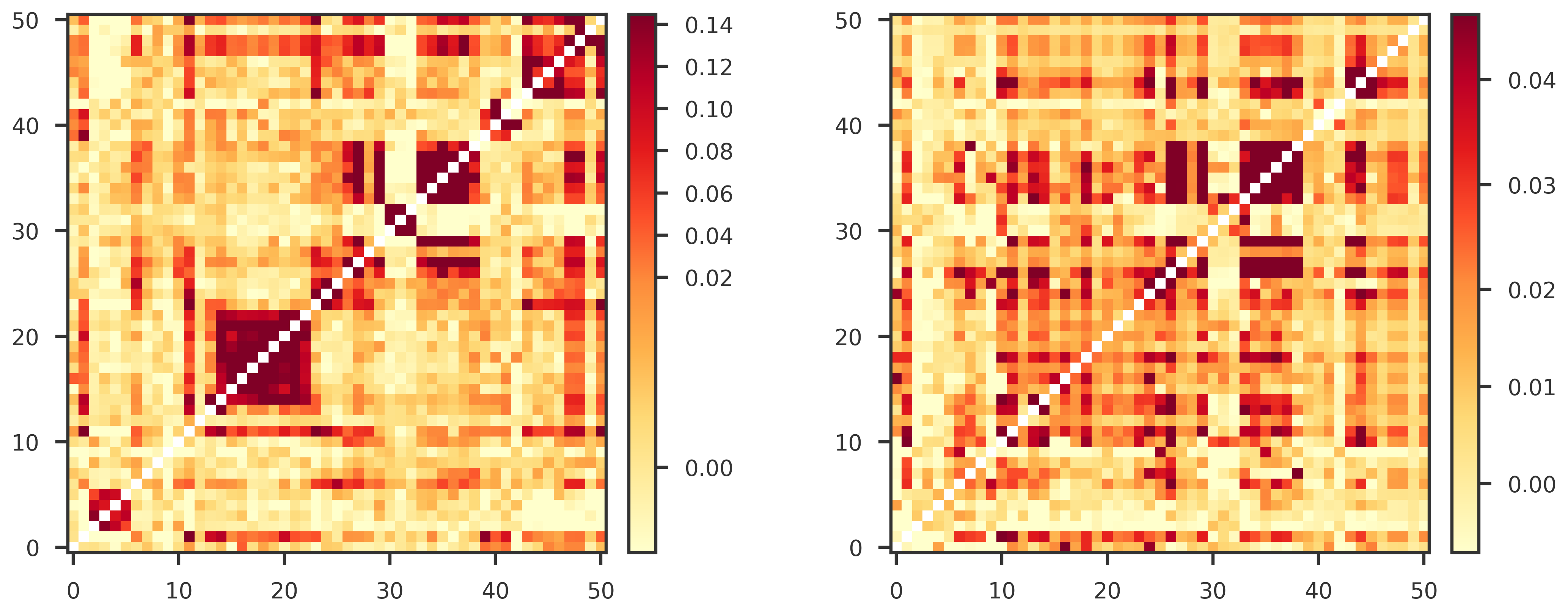
from scipy.stats import spearmanr, pearsonr
def make_heatmap_figure(A, B, title_A="", title_B=""):
def get_mpl_norm(X):
ok = np.isfinite(X)
vmin = np.quantile(X[ok], 0.1)
vmax = np.quantile(X[ok], 0.95)
vcenter = np.quantile(X[ok], 0.75)
return mpl_colors.TwoSlopeNorm(vmin=vmin, vcenter=vcenter, vmax=vmax)
A = A.to_numpy()
B = B.to_numpy()
fig = plt.figure(figsize = (16,8))
gs = fig.add_gridspec(nrows=1, ncols=2, wspace=0.4, hspace=0)
ax1 = fig.add_subplot(gs[0, 0])
ax2 = fig.add_subplot(gs[0, 1])
cmap1 = mpl_cmaps.get_cmap("YlOrRd").copy()
im1 = ax1.imshow(A, cmap=cmap1, norm=get_mpl_norm(A), origin='lower')
divider = make_axes_locatable(ax1)
cax = divider.append_axes("right", size="5%", pad=0.2)
cbar = plt.colorbar(im1, cax=cax, fraction=0.1)
ax1.set_title(title_A, pad=20)
im2 = ax2.imshow(B, cmap=cmap1, norm=get_mpl_norm(B), origin='lower')
divider = make_axes_locatable(ax2)
cax = divider.append_axes("right", size="5%", pad=0.2)
cbar = plt.colorbar(im2, cax=cax, fraction=0.1)
ax2.set_title(title_B, pad=20)
plt.show()
def offdiag_check(S, G, R, P, n_perm=10000, seed=0,thr=0.05):
"""
S = bivariate intercept (sampling covariance)
G = bivariate slope (genetic covariance)
Off-diagonals only
"""
S = np.asarray(S, float)
G = np.asarray(G, float)
R = np.asarray(R, float)
P = np.asarray(P, float)
iu = np.triu_indices_from(S, k=1)
x, y, rg, rg_p = np.abs(S[iu]), G[iu], R[iu], P[iu]
ok = np.isfinite(x) & np.isfinite(y) & np.isfinite(rg)
x, y, rg, rg_p = x[ok], y[ok], rg[ok], rg_p[ok]
r_obs = spearmanr(x, y).statistic # rank -> robust to the two different scales
for lo, hi in [(0, .05), (.05, .1), (.1, .2), (.2, .4), (.4, 2.01)]:
m = (np.abs(x) >= lo) & (np.abs(x) < hi)
if m.sum() > 5:
# print(f"|Sampling Covariance| ∈ [{lo},{hi}):\tn={m.sum():5d} ")
print(f"|Sampling Covariance| ∈ [{lo:.2f},{hi:.2f})"
f"\n\tn = {m.sum():5d}"
f"\n\tρ = {spearmanr(x[m], y[m]).statistic:+.3f}"
f"\n\tmedian|rg| = {np.median(np.abs(rg[m])):.3f}"
f"\n\t95th|rg| = {np.quantile(np.abs(rg[m]),.95):.3f}"
f"\n\tfrac_sig = {np.mean(rg_p[m]<thr):.3f}")
rng = np.random.default_rng(seed); n = S.shape[0]; null = np.empty(n_perm)
for b in range(n_perm):
p = rng.permutation(n)
null[b] = spearmanr(S[np.ix_(p, p)][iu][ok], y).statistic
p = (np.sum(np.abs(null) >= abs(r_obs)) + 1) / (n_perm + 1)
return dict(spearman=r_obs, pearson=pearsonr(x, y)[0], mantel_p=p, x=x, y=y)
def load_zscore(zscore_path):
df = pd.read_csv(Path(zscore_path), header=0, index_col=0, dtype={0: str})
df.index = df.index.map(str)
df.columns = df.columns.map(str)
return df