def get_r_scaled(x, scale="log2"):
x = np.asarray(x, dtype=float)
powers = np.arange(np.ceil(np.log2(x.min())), np.floor(np.log2(x.max())) + 1)
xlabels = 2 ** powers
if scale == "log10":
xscale = np.log10(x)
xticks = np.log10(xlabels)
elif scale == "log2":
xscale = np.log2(x)
xticks = np.log2(xlabels)
else:
xscale = x
xticks = xlabels
xlabel_str = [f"{r:g}" for r in xlabels]
return xscale, xticks, xlabel_str
def centers_to_edges(x):
x = np.asarray(x, dtype=float)
edges = np.empty(len(x) + 1)
edges[1:-1] = 0.5 * (x[:-1] + x[1:])
edges[0] = x[0] - 0.5 * (x[1] - x[0])
edges[-1] = x[-1] + 0.5 * (x[-1] - x[-2])
return edges
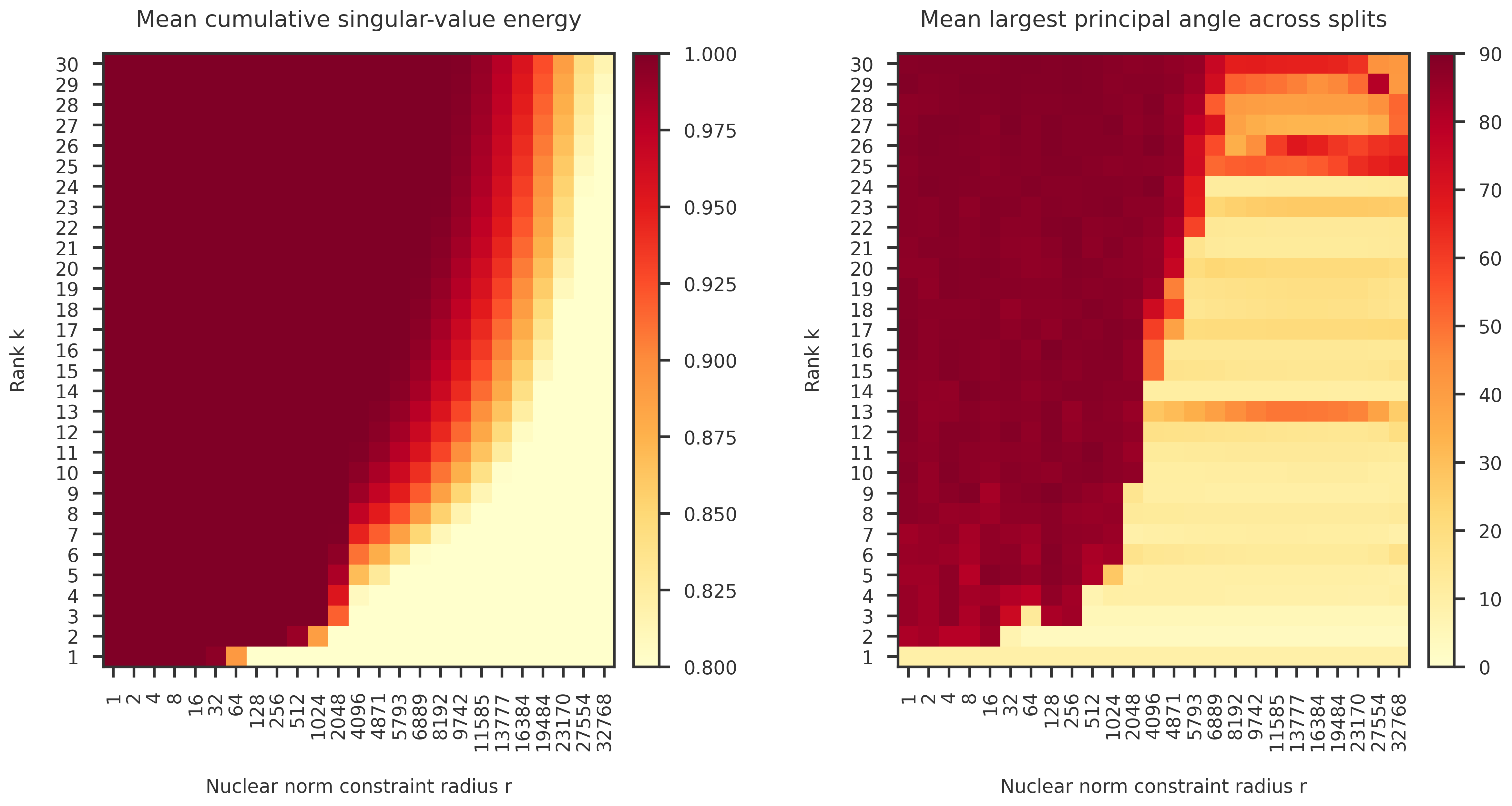
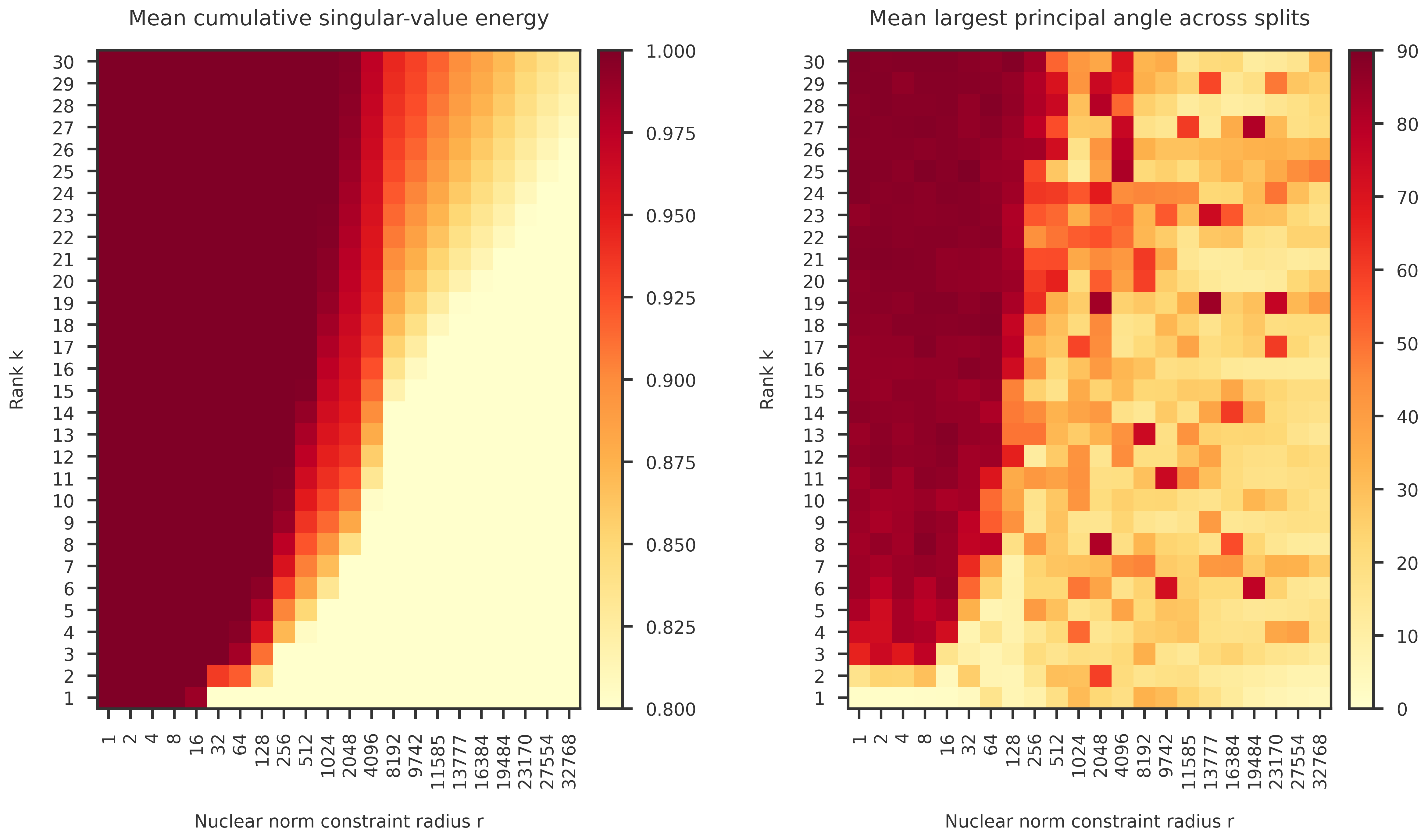
def plot_heatmap(ax, X, rank_list, k_list,
vmin=0, vcenter=0.9, vmax=1.0,
scale="log2"):
cmap1 = mpl_cmaps.get_cmap("YlOrRd").copy()
cmap1.set_bad("w")
norm1 = mpl_colors.TwoSlopeNorm(vmin=vmin, vcenter=vcenter, vmax=vmax)
r, rticks, rlabels = get_r_scaled(rank_list, scale=scale)
x_edges = centers_to_edges(r)
y_edges = np.arange(len(k_list) + 1) - 0.5
im1 = ax.pcolormesh(x_edges, y_edges, X, cmap=cmap1, norm=norm1, shading="auto")
# match imshow(origin="upper")
ax.set_ylim(len(k_list) - 0.5, -0.5)
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.2)
cbar = plt.colorbar(im1, cax=cax, fraction=0.1)
ax.set_xlabel("Nuclear norm constraint radius r")
ax.set_ylabel("Rank k")
ax.set_yticks(np.arange(len(k_list)))
ax.set_yticklabels([str(int(k)) for k in k_list])
ax.set_xticks(rticks)
ax.set_xticklabels([str(int(r)) for r in rlabels], rotation=90)
return im1
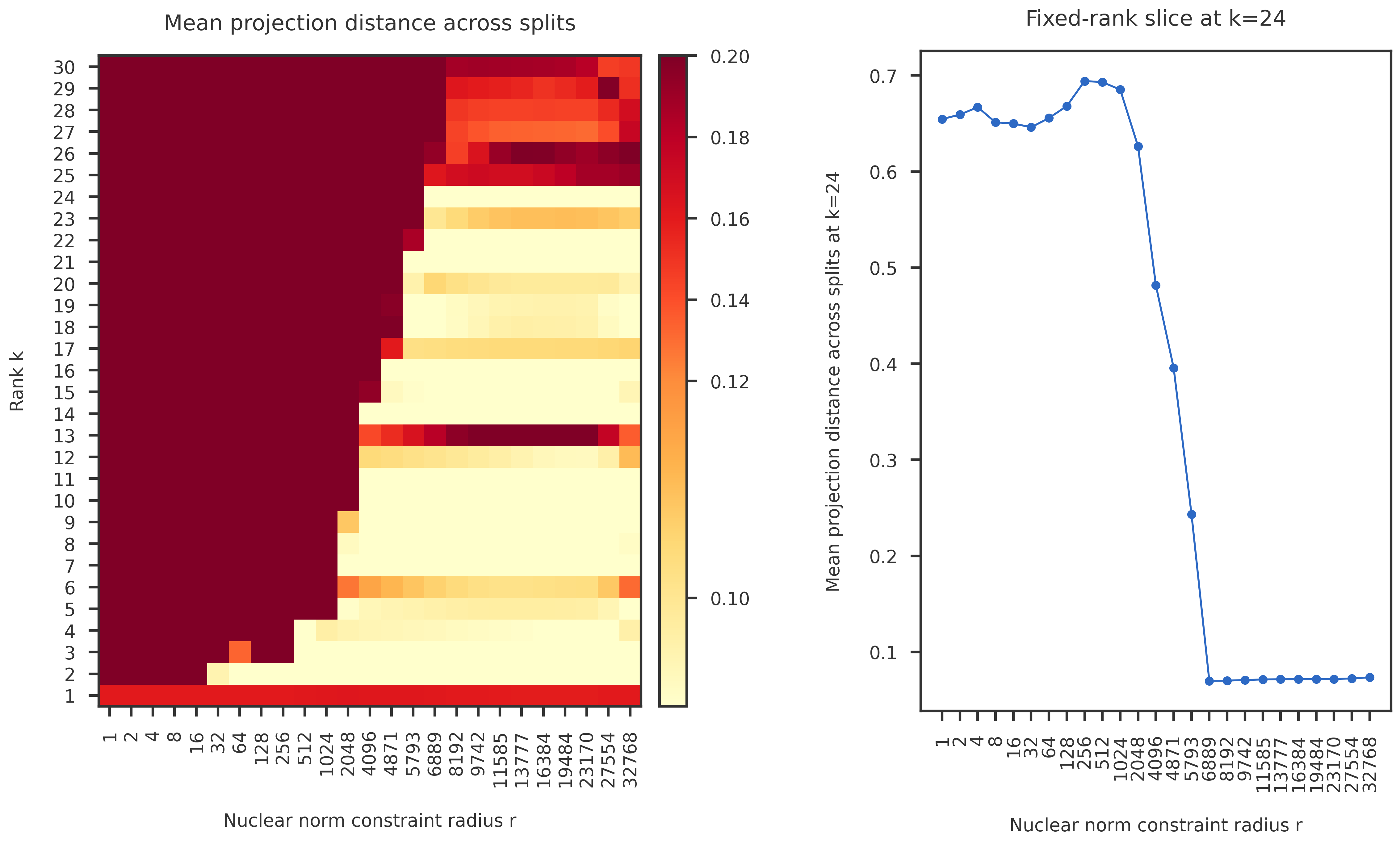
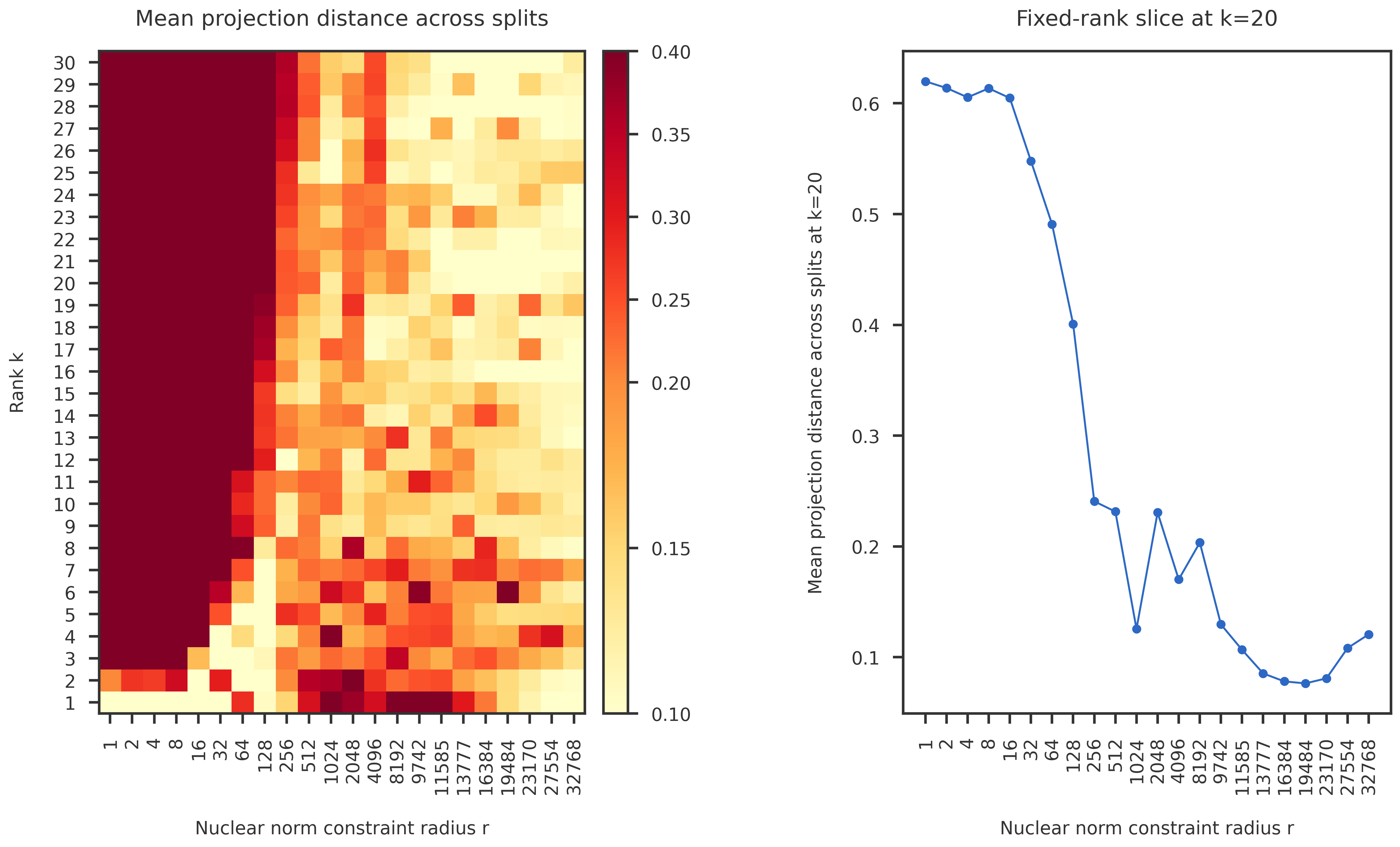
def make_projection_distance_figure(prefix,
vmin=0.09, vcenter=0.12, vmax=0.2):
smooth_window = 5
records = load_stability_jsons(stability_out_dir, prefix)
dist_df = build_by_k_metrics_grid(records, "mean_dist", duplicate="first")
smoothed_dist_df = dist_df.rolling(window=smooth_window, center=True, min_periods=1).mean()
se_dist_df = build_by_k_metrics_grid(records, "se_dist", duplicate="first")
rank_list = dist_df.columns.to_numpy()
k_list = dist_df.index.to_numpy()
fig = plt.figure(figsize=(20, 15), constrained_layout=True)
gs = fig.add_gridspec(nrows=2, ncols=2,
width_ratios=[1, 1], # heatmap, line plot
wspace=0.2, hspace=0.05,
)
ax1 = fig.add_subplot(gs[0, 0])
ax2 = fig.add_subplot(gs[0, 1])
ax3 = fig.add_subplot(gs[1, 0])
ax4 = fig.add_subplot(gs[1, 1])
im1 = plot_heatmap(ax1, dist_df.to_numpy(), rank_list, k_list,
vmin=vmin, vcenter=vcenter, vmax=vmax)
ax1.set_title("Mean projection distance across splits", pad = 20)
ax1.text(-0.1, 1.1, "(a)", transform=ax1.transAxes, fontweight='bold')
# Plot rows of the heatmap as a line plot.
# Makes it easier to see the plateau onset for chosen ranks.
k_choose = [8, 10, 15, 20, 25]
r, rticks, rlabels = get_r_scaled(rank_list, scale='log2')
rlabels = [f"{int(r):d}" for r in rlabels]
for k in k_choose:
y = dist_df.loc[k].to_numpy()
se = se_dist_df.loc[k].to_numpy()
ax2.plot(r, y, 'o-', label=f"{k:d}")
ax2.fill_between(r, y - se, y + se, alpha=0.2)
ax2.set_xlabel("Nuclear norm constraint radius r")
ax2.set_ylabel(f"Mean projection distance")
ax2.set_xticks(rticks)
ax2.set_xticklabels(rlabels, rotation=90)
ax2.set_title(f"Slices over r at selected k", pad = 20)
ax2.legend(loc = 'upper right', frameon = False, handlelength = 2, ncol = 2)
ax2.text(-0.1, 1.1, "(b)", transform=ax2.transAxes, fontweight='bold')
# Plot columns of the heatmap as a line plot.
# Makes it easier to see the variation over ranks.
r_choose = [128, 256, 512, 1024, 2048, 4096, 8192, 16384]
for r in r_choose:
y = smoothed_dist_df[r].to_numpy()
x = np.arange(len(y))
se = se_dist_df[r].to_numpy()
ax3.plot(x, y, 'o-', label=f"{r:d}")
ax3.fill_between(x, y - se, y + se, alpha=0.2)
ax3.set_xlabel("Rank k")
ax3.set_ylabel(f"Mean projection distance")
ax3.set_xticks(x)
ax3.set_xticklabels(k_list, rotation=90)
ax3.set_title(f"Slices over k at selected r, smoothed over 5 k-neighbors", pad = 20)
ax3.legend(loc = 'upper left', bbox_to_anchor=(0.2, 0.95), frameon = False, handlelength = 2, ncol = 2)
ax3.text(-0.1, 1.1, "(c)", transform=ax3.transAxes, fontweight='bold')
# Plot rows of the heatmap as a line plot.
# Makes it easier to see the plateau onset for chosen ranks.
k_choose = [8, 10, 15, 20, 25]
r, rticks, rlabels = get_r_scaled(rank_list, scale='log2')
rlabels = [f"{int(r):d}" for r in rlabels]
for k in k_choose:
y = smoothed_dist_df.loc[k].to_numpy()
ax4.plot(r, y, 'o-', label=f"{k:d}")
ax4.set_xlabel("Nuclear norm constraint radius r")
ax4.set_ylabel(f"Mean projection distance")
ax4.set_xticks(rticks)
ax4.set_xticklabels(rlabels, rotation=90)
ax4.set_title(f"Slices over r at selected k, smoothed over {smooth_window:d} k-neighbors", pad = 20)
ax4.legend(loc = 'upper right', frameon = False, handlelength = 2, ncol = 2)
ax4.text(-0.1, 1.1, "(d)", transform=ax4.transAxes, fontweight='bold')
fig.savefig(
fig_dir / f"{prefix}_projection_distance.png",
bbox_inches="tight",
)
plt.close(fig)
# plt.show()
for prefix in PREFIXES:
vmin, vcenter, vmax = 0.09, 0.18, 0.30
if prefix == "pgd_afw_nnm_corr":
vmin, vcenter, vmax = 0.05, 0.3, 0.6
make_projection_distance_figure(prefix, vmin=vmin, vcenter=vcenter, vmax=vmax)