def random_jitter(xvals, yvals, d = 0.1):
xjitter = [x + np.random.randn(len(y)) * d for x, y in zip(xvals, yvals)]
return xjitter
def boxplot_scores(variable, variable_values,
methods = methods, score_names = score_names,
dscout = dscout, method_colors = method_colors):
nmethods = len(methods)
nvariables = len(variable_values)
nscores = len(score_names)
figh = 6
figw = (nscores * figh) + (nscores - 1)
fig = plt.figure(figsize = (figw, figh))
axs = [fig.add_subplot(1, nscores, x+1) for x in range(nscores)]
boxs = {x: None for x in methods.keys()}
for i, (score_name, score_label) in enumerate(score_names.items()):
scores = get_scores_from_dataframe(dscout, score_name, variable, variable_values)
for j, mkey in enumerate(methods.keys()):
boxcolor = method_colors[mkey]
boxface = f'#{boxcolor[1:]}80'
medianprops = dict(linewidth=0, color = boxcolor)
whiskerprops = dict(linewidth=2, color = boxcolor)
boxprops = dict(linewidth=2, color = boxcolor, facecolor = boxface)
flierprops = dict(marker='o', markerfacecolor=boxface, markersize=3, markeredgecolor = boxcolor)
xpos = [x * (nmethods + 1) + j for x in range(nvariables)]
boxs[mkey] = axs[i].boxplot(scores[mkey], positions = xpos,
showcaps = False, showfliers = False,
widths = 0.7, patch_artist = True, notch = False,
flierprops = flierprops, boxprops = boxprops,
medianprops = medianprops, whiskerprops = whiskerprops)
axs[i].scatter(random_jitter(xpos, scores[mkey]), scores[mkey],
edgecolor = boxcolor, facecolor = boxface, linewidths = 1,
s = 10)
xcenter = [x * (nmethods + 1) + (nmethods - 1) / 2 for x in range(nvariables)]
axs[i].set_xticks(xcenter)
axs[i].set_xticklabels(variable_values)
axs[i].set_xlabel(variable)
axs[i].set_ylabel(score_label)
xlim_low = 0 - (nvariables - 1) / 2
#xlim_high = (nvariables - 1) * (nmethods + 1) + (nmethods - 1) + (nvariables - 1) / 2
xlim_high = (nmethods + 1.5) * nvariables - 2.5
axs[i].set_xlim( xlim_low, xlim_high )
plt.tight_layout()
return axs, boxs
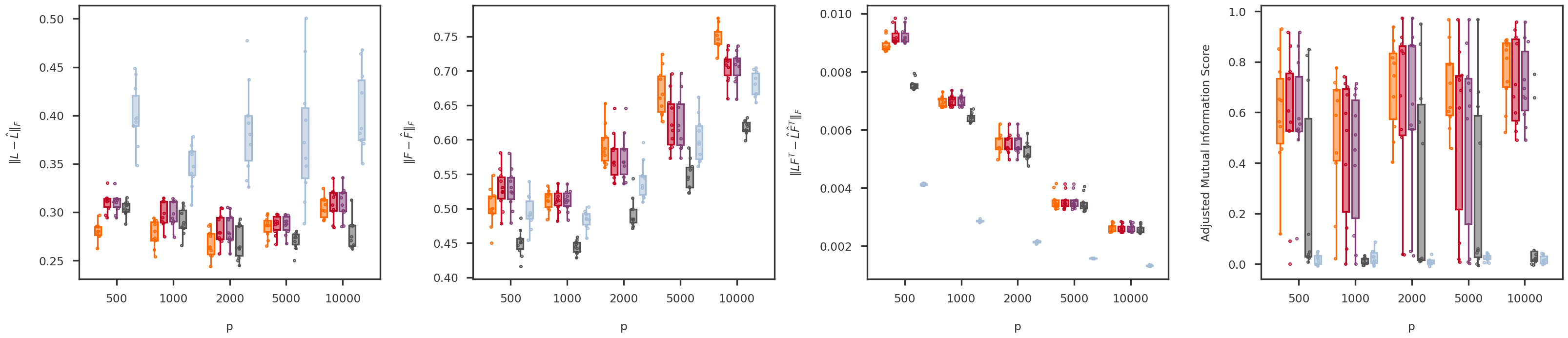
variable = 'p'
variable_values = [500, 1000, 2000, 5000, 10000]
axs, boxs = boxplot_scores(variable, variable_values)
plt.show()