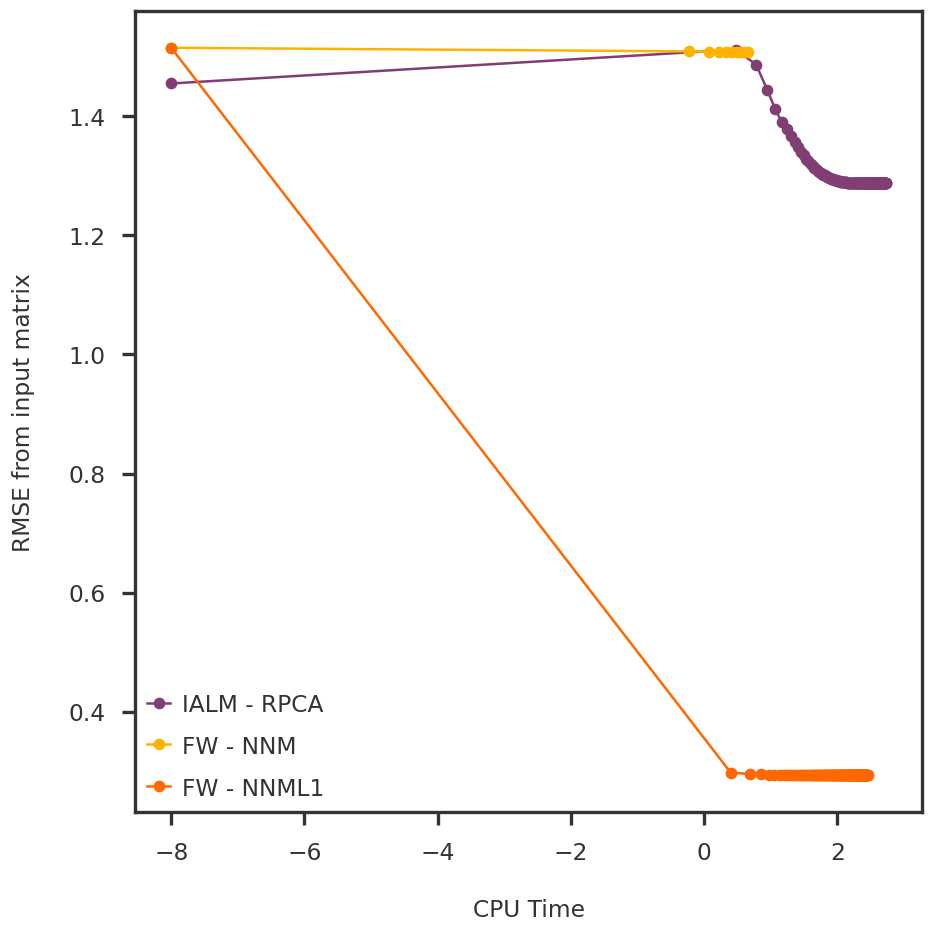
For models (1) and (3), we use the Frank-Wolfe method, and for model (2), we use the inexact augmented Lagrangian method (IALM) with a slight modification of the step-size update (borrowing the ADMM updates of Boyd et. al.). We use a simple simulation (as described previously) with additive Gaussian noise to realistically mimic the z-scores obtained from multiple GWAS.
Getting setup
We have now implemented a Python software to call the different methods with flexibility to choose different input options.
Code
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom pymir import mpl_stylesheetfrom pymir import mpl_utilsmpl_stylesheet.banskt_presentation(splinecolor ='black', dpi =120, colors ='kelly')import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom pymir import mpl_stylesheetfrom pymir import mpl_utilsmpl_stylesheet.banskt_presentation(splinecolor ='black', dpi =120, colors ='kelly')import syssys.path.append("../utils/")import histogram as mpy_histogramimport simulate as mpy_simulateimport plot_functions as mpy_plotfnfrom nnwmf.optimize import IALMimport syssys.path.append("../utils/")import histogram as mpy_histogramimport simulate as mpy_simulateimport plot_functions as mpy_plotfnfrom nnwmf.optimize import IALMfrom nnwmf.optimize import FrankWolfefrom nnwmf.utils import model_errors as merr
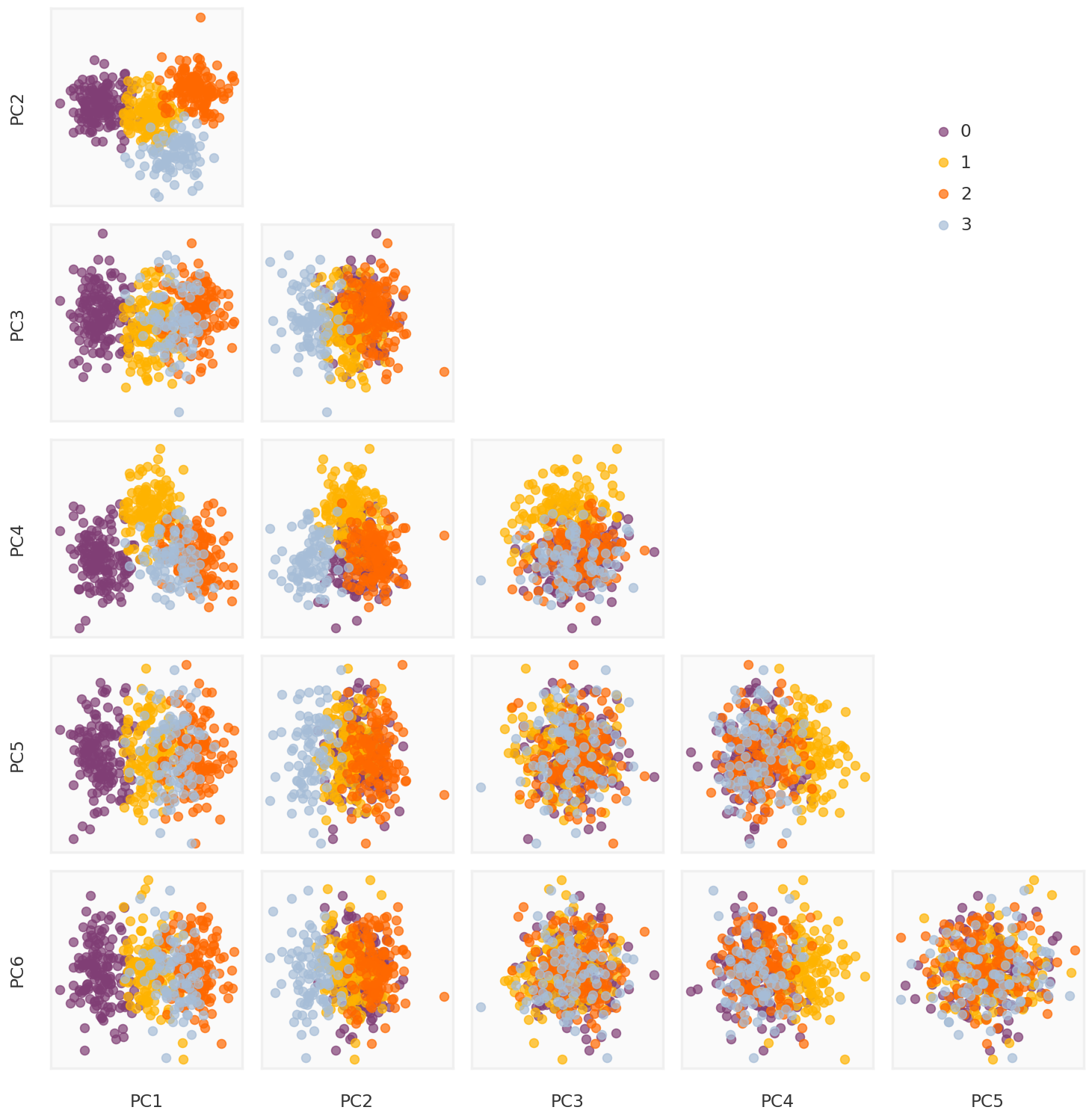
unique_labels =list(range(len(sample_indices)))class_labels = [Nonefor x inrange(ngwas)]for k, idxs inenumerate(sample_indices):for i in idxs: class_labels[i] = k
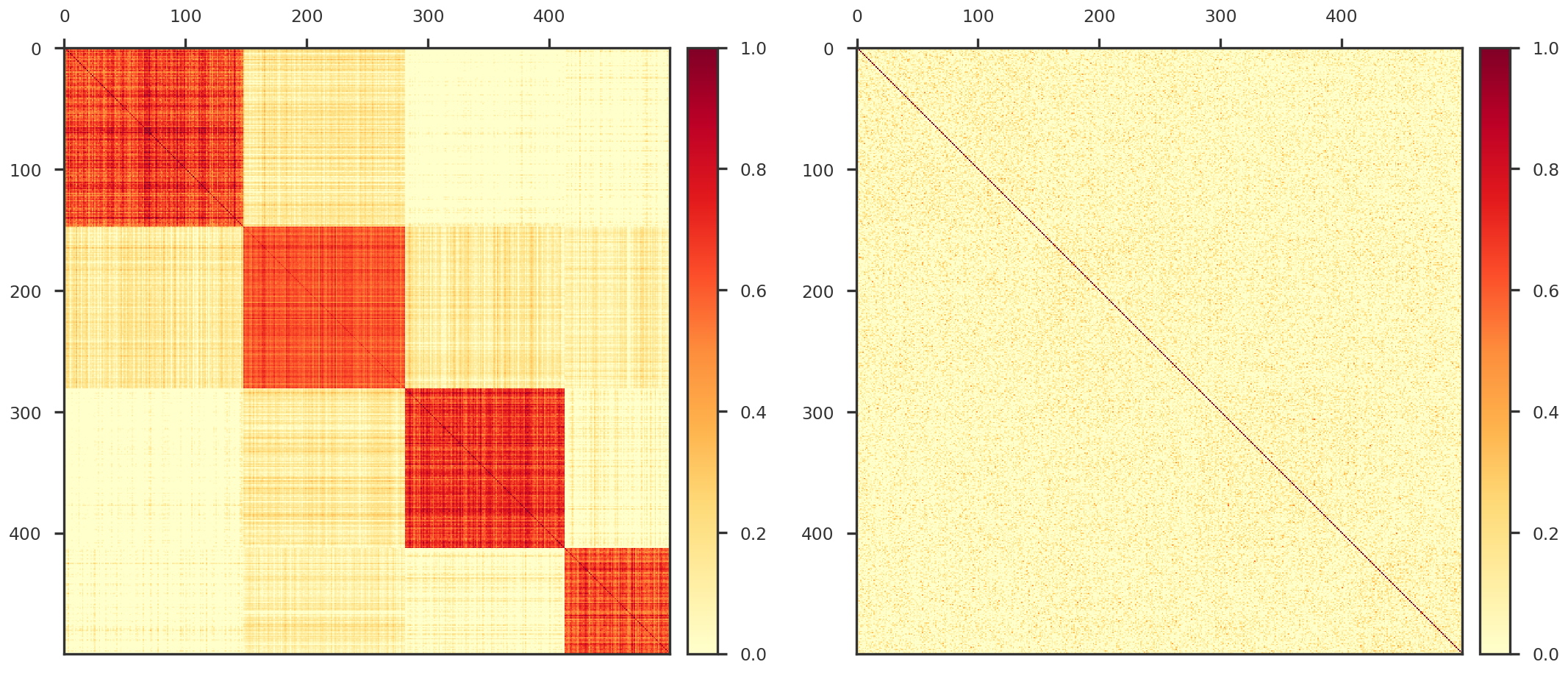
In Figure 1, we show the underlying structure of our simulated data. On the left panel, we show the covariance of the true loadings and on the right panel, we show the covariance of the observed data (strong noise removes the underlying correlation)
We do a little cheating here. Instead of cross-validation, we directly use the known rank of the underlying true data. However, based on my previous work, I know that cross-validation does provide the correct rank.
2023-08-02 14:47:37,144 | nnwmf.optimize.frankwolfe | INFO | Iteration 0. Step size 1.000. Duality Gap 5383.02
FW - NNML1
For the third model, we use the sparse noise threshold from the RPCA result and the rank from the true data. I have not checked cross-validation results for this method yet.