def do_standardize(Z, axis = 0, center = True, scale = True):
'''
Standardize (divide by standard deviation)
and/or center (subtract mean) of a given numpy array Z
axis: the direction along which the std / mean is aggregated.
In other words, this axis is collapsed. For example,
axis = 0, means the rows will aggregated (collapsed).
In the output, the mean will be zero and std will be 1
along the remaining axes.
For a 2D array (matrix), use axis = 0 for column standardization
(with mean = 0 and std = 1 along the columns, axis = 1).
Simularly, use axis = 1 for row standardization
(with mean = 0 and std = 1 along the rows, axis = 0).
center: whether or not to subtract mean.
scale: whether or not to divide by std.
'''
dim = Z.ndim
if scale:
Znew = Z / np.std(Z, axis = axis, keepdims = True)
else:
Znew = Z.copy()
if center:
Znew = Znew - np.mean(Znew, axis = axis, keepdims = True)
return Znew
def get_equicorr_feature(n, p, rho = 0.8, seed = None, standardize = True):
'''
Return a matrix X of size n x p with correlated features.
The matrix S = X^T X has unit diagonal entries and constant off-diagonal entries rho.
'''
if seed is not None: np.random.seed(seed)
iidx = np.random.normal(size = (n , p))
comR = np.random.normal(size = (n , 1))
x = comR * np.sqrt(rho) + iidx * np.sqrt(1 - rho)
# standardize if required
if standardize:
x = do_standardize(x)
return x
def get_blockdiag_features(n, p, rholist, groups, rho_bg = 0.0, seed = None, standardize = True):
'''
Return a matrix X of size n x p with correlated features.
The matrix S = X^T X has unit diagonal entries and
k blocks of matrices, whose off-diagonal entries
are specified by elements of `rholist`.
rholist: list of floats, specifying the correlation within each block
groups: list of integer arrays, each array contains the indices of the blocks.
'''
np.testing.assert_equal(len(rholist), len(groups))
if seed is not None: np.random.seed(seed)
iidx = get_equicorr_feature(n, p, rho = rho_bg)
# number of blocks
k = len(rholist)
# zero initialize
x = iidx.copy() #np.zeros_like(iidx)
for rho, grp in zip(rholist, groups):
comR = np.random.normal(size = (n, 1))
x[:, grp] = np.sqrt(rho) * comR + np.sqrt(1 - rho) * iidx[:, grp]
# standardize if required
if standardize:
x = do_standardize(x)
return x
def get_blockdiag_matrix(n, rholist, groups):
R = np.ones((n, n))
for i, (idx, rho) in enumerate(zip(groups, rholist)):
nblock = idx.shape[0]
xblock = np.ones((nblock, nblock)) * rho
R[np.ix_(idx, idx)] = xblock
return R
# def get_correlated_features (n, p, R, seed = None, standardize = True, method = 'cholesky'):
# '''
# method: Choice of method, cholesky or eigenvector or blockdiag.
# '''
# # Generate samples from independent normally distributed random
# # variables (with mean 0 and std. dev. 1).
# x = norm.rvs(size=(p, n))
# # We need a matrix `c` for which `c*c^T = r`. We can use, for example,
# # the Cholesky decomposition, or the we can construct `c` from the
# # eigenvectors and eigenvalues.
# if method == 'cholesky':
# # Compute the Cholesky decomposition.
# c = cholesky(r, lower=True)
# else:
# # Compute the eigenvalues and eigenvectors.
# evals, evecs = eigh(r)
# # Construct c, so c*c^T = r.
# c = np.dot(evecs, np.diag(np.sqrt(evals)))
# # Convert the data to correlated random variables.
# y = np.dot(c, x)
# return y
def get_sample_indices(ntrait, ngwas, shuffle = True):
'''
Distribute the samples in the categories (classes)
'''
rs = 0.6 * np.random.rand(ntrait) + 0.2 # random sample from [0.2, 0.8)
z = np.array(np.round((rs / np.sum(rs)) * ngwas), dtype = int)
z[-1] = ngwas - np.sum(z[:-1])
tidx = np.arange(ngwas)
if shuffle:
np.random.shuffle(tidx)
bins = np.zeros(ntrait + 1, dtype = int)
bins[1:] = np.cumsum(z)
sdict = {i : np.sort(tidx[bins[i]:bins[i+1]]) for i in range(ntrait)}
return sdict
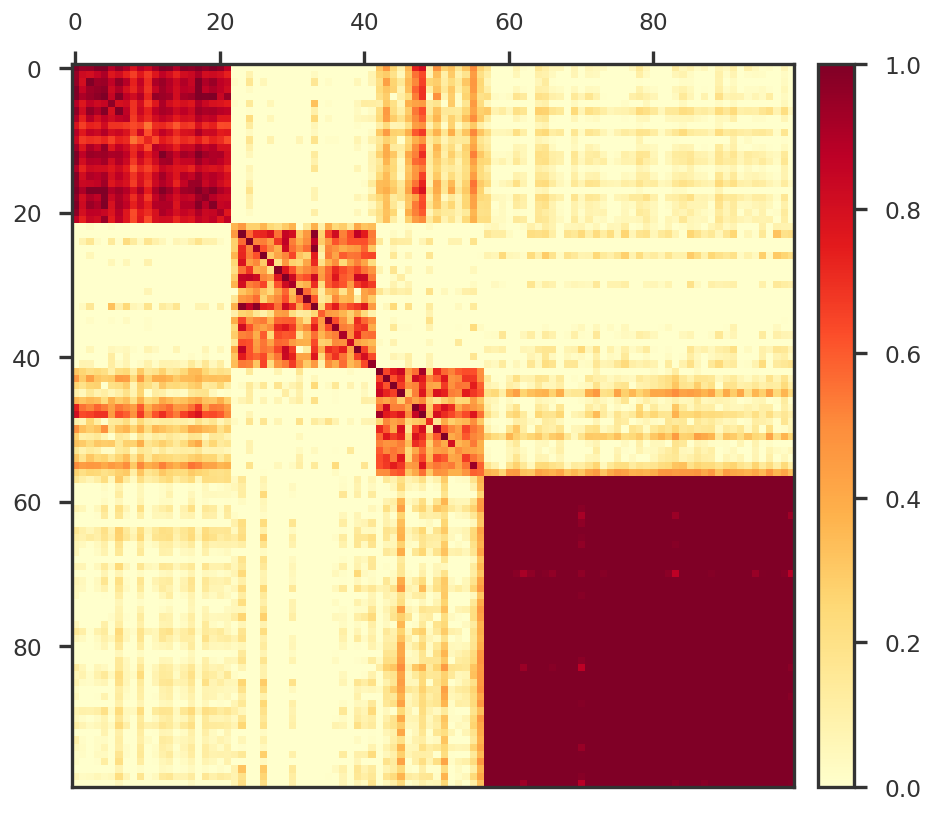
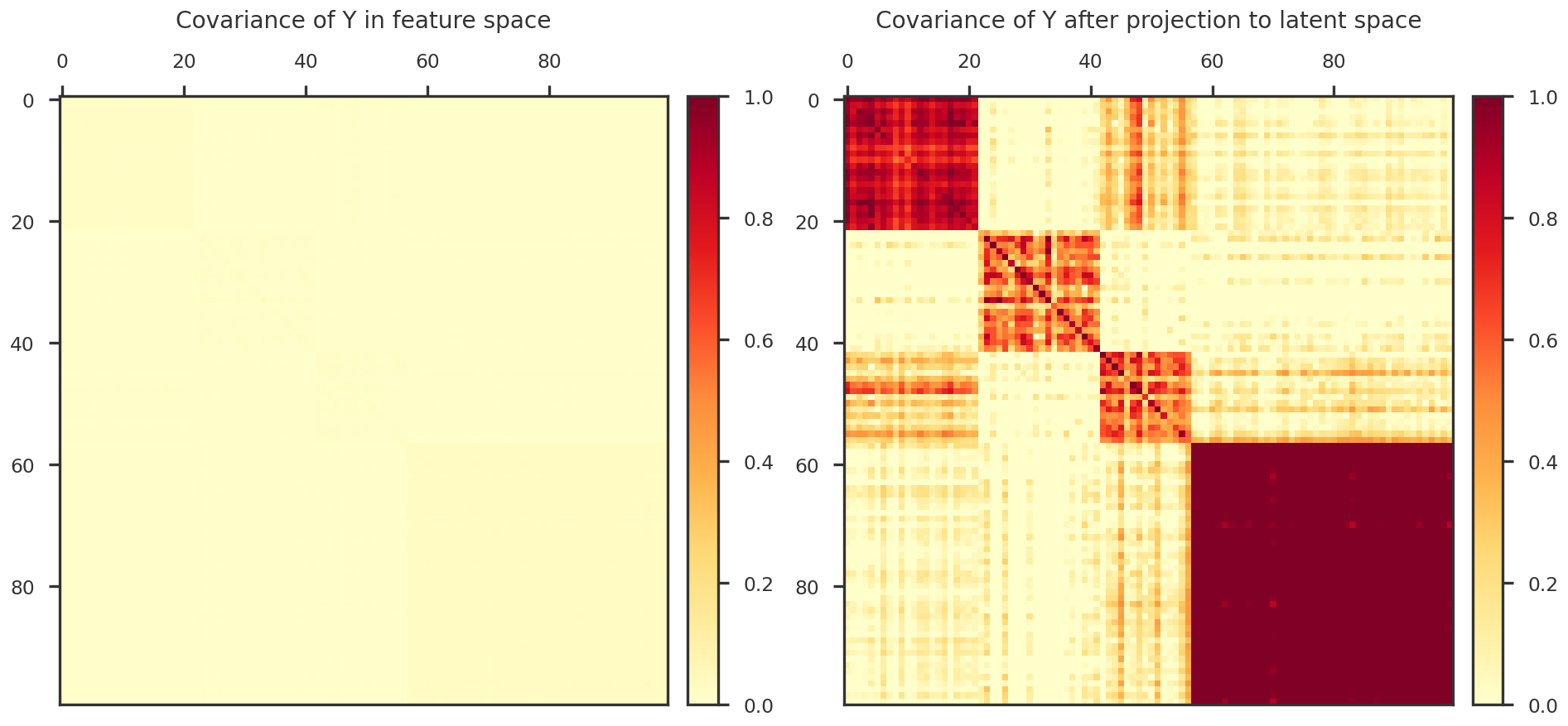
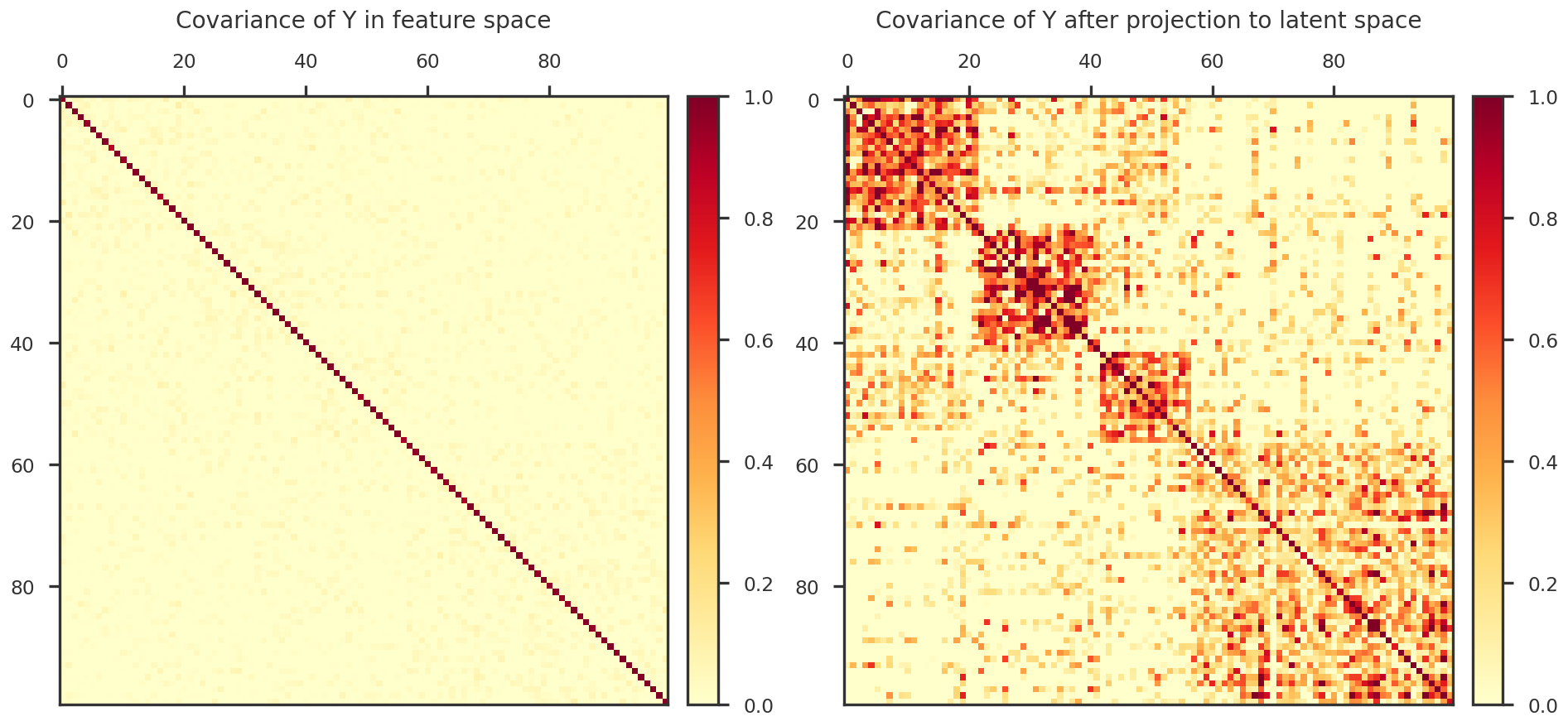
def plot_covariance_heatmap(ax, X):
return plot_heatmap(ax, np.cov(X))
def plot_heatmap(ax, X):
'''
Helps to plot a heatmap
'''
cmap1 = mpl_cmaps.get_cmap("YlOrRd").copy()
cmap1.set_bad("w")
norm1 = mpl_colors.TwoSlopeNorm(vmin=0., vcenter=0.5, vmax=1.)
im1 = ax.imshow(X.T, cmap = cmap1, norm = norm1, interpolation='nearest', origin = 'upper')
ax.tick_params(bottom = False, top = True, left = True, right = False,
labelbottom = False, labeltop = True, labelleft = True, labelright = False)
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.2)
cbar = plt.colorbar(im1, cax=cax, fraction = 0.1)
return
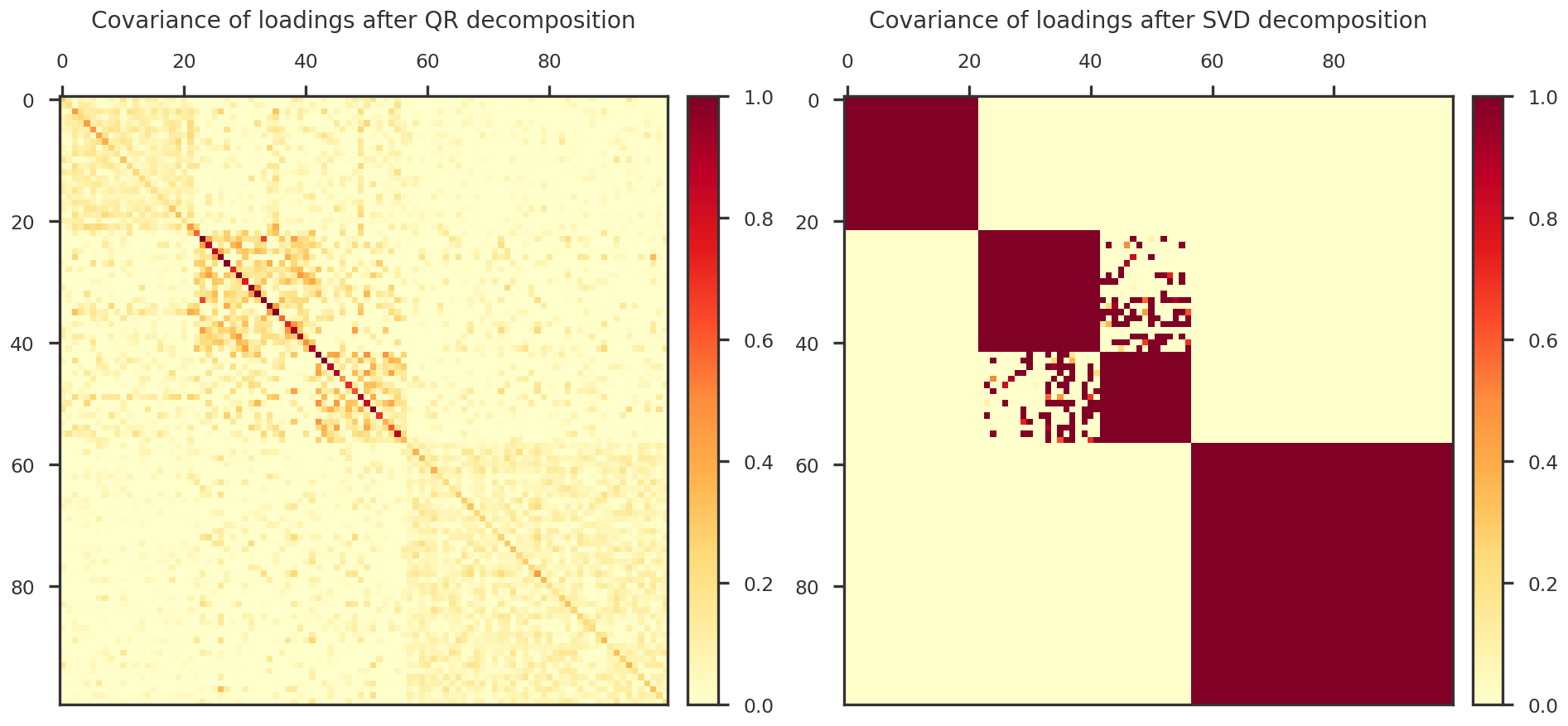
def reduce_dimension_svd(X, nfeature = None):
if k is None: k = int(X.shape[1] / 10)
k = max(1, k)
U, S, Vt = np.linalg.svd(X)
Uk = U[:, :k]
Sk = S[:k]
return Uk @ Sk
# L_qr_ortho, L_qr_eig = orthogonalize_qr(do_standardize(L_full))
# #idsort = np.argsort(L_eig)[::-1]
# #idselect = idsort[:nfctr]
# idselect = np.arange(nfctr)
# L_qr = L_qr_ortho[:, idselect] @ np.diag(L_qr_eig[idselect])
# L_svd_ortho, L_svd_eig = orthogonalize_svd(do_standardize(L_full), k = nfctr)
# L_svd = L_svd_ortho @ np.diag(L_svd_eig)